CMU - Gen AI Lab RAG
CMU - Gen AI Lab RAG
Manual document search can be slow, inconsistent, and inefficient. This project leverages Retrieval Augmented Generation (RAG) to enable dynamic, contextually accurate querying of the CMU Student Handbook, making policy information retrieval instant, scalable, and reliable.

VIsion & Problem Statement
VIsion & Problem Statement
Vision:
Enable a robust, user-friendly system for retrieving detailed and accurate university policy information using modern RAG techniques integrated with Large Language Models (LLMs).
Problem Statement:
Students and administrators often struggle with manually locating specific university policies across lengthy documents. Existing search methods are keyword-based and often fail to capture semantic nuances.
PolicyRetriever addresses this by implementing an RAG-based pipeline that improves search relevance, semantic understanding, and information accessibility.
Vision:
Enable a robust, user-friendly system for retrieving detailed and accurate university policy information using modern RAG techniques integrated with Large Language Models (LLMs).
Problem Statement:
Students and administrators often struggle with manually locating specific university policies across lengthy documents. Existing search methods are keyword-based and often fail to capture semantic nuances.
PolicyRetriever addresses this by implementing an RAG-based pipeline that improves search relevance, semantic understanding, and information accessibility.
VIsion & Problem Statement
Vision:
Enable a robust, user-friendly system for retrieving detailed and accurate university policy information using modern RAG techniques integrated with Large Language Models (LLMs).
Problem Statement:
Students and administrators often struggle with manually locating specific university policies across lengthy documents. Existing search methods are keyword-based and often fail to capture semantic nuances.
PolicyRetriever addresses this by implementing an RAG-based pipeline that improves search relevance, semantic understanding, and information accessibility.
Product Goal
Product Goal
Develop and evaluate a scalable RAG pipeline capable of retrieving relevant policy information from the CMU Student Handbook with high semantic accuracy and user interpretability.
Develop and evaluate a scalable RAG pipeline capable of retrieving relevant policy information from the CMU Student Handbook with high semantic accuracy and user interpretability.
Product Goal
Develop and evaluate a scalable RAG pipeline capable of retrieving relevant policy information from the CMU Student Handbook with high semantic accuracy and user interpretability.
User Stories
User Stories
Title | As a/an | I want to | So that |
|---|---|---|---|
Find Specific Policies | Student | Search for specific CMU policies quickly | I can get clear answers without reading the full handbook |
Enable Semantic Search | Researcher | Retrieve contextually relevant sections even with vague queries | I can find information even if I don't use exact handbook wording |
Evaluate Retrieval Quality | Project Team Member | Experiment with different similarity metrics and chunk sizes | I can optimize the relevance and precision of retrieved documents |
Analyze Search Efficiency | Project Team Member | Compare how different 'k' values affect retrieval quality | I can recommend optimal settings for future RAG deployments |
Visualize Results | Project Team Member | Structure and present query responses cleanly for analysis | I can generate insights for improving system performance |
Title | As a/an | I want to | So that |
|---|---|---|---|
Find Specific Policies | Student | Search for specific CMU policies quickly | I can get clear answers without reading the full handbook |
Enable Semantic Search | Researcher | Retrieve contextually relevant sections even with vague queries | I can find information even if I don't use exact handbook wording |
Evaluate Retrieval Quality | Project Team Member | Experiment with different similarity metrics and chunk sizes | I can optimize the relevance and precision of retrieved documents |
Analyze Search Efficiency | Project Team Member | Compare how different 'k' values affect retrieval quality | I can recommend optimal settings for future RAG deployments |
Visualize Results | Project Team Member | Structure and present query responses cleanly for analysis | I can generate insights for improving system performance |
User Stories
Title | As a/an | I want to | So that |
|---|---|---|---|
Find Specific Policies | Student | Search for specific CMU policies quickly | I can get clear answers without reading the full handbook |
Enable Semantic Search | Researcher | Retrieve contextually relevant sections even with vague queries | I can find information even if I don't use exact handbook wording |
Evaluate Retrieval Quality | Project Team Member | Experiment with different similarity metrics and chunk sizes | I can optimize the relevance and precision of retrieved documents |
Analyze Search Efficiency | Project Team Member | Compare how different 'k' values affect retrieval quality | I can recommend optimal settings for future RAG deployments |
Visualize Results | Project Team Member | Structure and present query responses cleanly for analysis | I can generate insights for improving system performance |

Core Features
Core Features
Feature | Description | Priority |
|---|---|---|
Chunking Strategy Implementation | Text preprocessing using Recursive Text Splitting to preserve context | P1 |
Embedding Generation | Create semantic embeddings for chunks using OpenAI Ada-002 | P1 |
Vector Store Construction | Build and manage a Pinecone vector store for fast similarity search | P1 |
Query Parameter Optimization | Test different 'k' values and analyze impacts on retrieval quality | P2 |
Similarity Metric Selection | Evaluate and select the best similarity metrics (Cosine vs Dot Product vs Euclidean) | P1 |
LLM Query Integration (rag_llm) | Connect retrieved documents to LLM prompting for enhanced response generation | P2 |
Evaluation Metrics & Analysis | Use semantic similarity scoring and manual review for retrieval quality assessment | P2 |
Feature | Description | Priority |
|---|---|---|
Chunking Strategy Implementation | Text preprocessing using Recursive Text Splitting to preserve context | P1 |
Embedding Generation | Create semantic embeddings for chunks using OpenAI Ada-002 | P1 |
Vector Store Construction | Build and manage a Pinecone vector store for fast similarity search | P1 |
Query Parameter Optimization | Test different 'k' values and analyze impacts on retrieval quality | P2 |
Similarity Metric Selection | Evaluate and select the best similarity metrics (Cosine vs Dot Product vs Euclidean) | P1 |
LLM Query Integration (rag_llm) | Connect retrieved documents to LLM prompting for enhanced response generation | P2 |
Evaluation Metrics & Analysis | Use semantic similarity scoring and manual review for retrieval quality assessment | P2 |
Core Features
Feature | Description | Priority |
|---|---|---|
Chunking Strategy Implementation | Text preprocessing using Recursive Text Splitting to preserve context | P1 |
Embedding Generation | Create semantic embeddings for chunks using OpenAI Ada-002 | P1 |
Vector Store Construction | Build and manage a Pinecone vector store for fast similarity search | P1 |
Query Parameter Optimization | Test different 'k' values and analyze impacts on retrieval quality | P2 |
Similarity Metric Selection | Evaluate and select the best similarity metrics (Cosine vs Dot Product vs Euclidean) | P1 |
LLM Query Integration (rag_llm) | Connect retrieved documents to LLM prompting for enhanced response generation | P2 |
Evaluation Metrics & Analysis | Use semantic similarity scoring and manual review for retrieval quality assessment | P2 |
Success Metrics
Success Metrics
Metric | Description |
|---|---|
Retrieval Accuracy | % of queries retrieving correct policy information |
Top-k Retrieval Effectiveness | Impact of different 'k' values on relevance and noise |
Embedding Similarity Consistency | Cosine similarity scores between embeddings and queries |
Response Contextual Match Rate | % of LLM-generated responses matching retrieved document intent |
Query Latency | Average time to return top-k search results |
Metric | Description |
|---|---|
Retrieval Accuracy | % of queries retrieving correct policy information |
Top-k Retrieval Effectiveness | Impact of different 'k' values on relevance and noise |
Embedding Similarity Consistency | Cosine similarity scores between embeddings and queries |
Response Contextual Match Rate | % of LLM-generated responses matching retrieved document intent |
Query Latency | Average time to return top-k search results |
Success Metrics
Metric | Description |
|---|---|
Retrieval Accuracy | % of queries retrieving correct policy information |
Top-k Retrieval Effectiveness | Impact of different 'k' values on relevance and noise |
Embedding Similarity Consistency | Cosine similarity scores between embeddings and queries |
Response Contextual Match Rate | % of LLM-generated responses matching retrieved document intent |
Query Latency | Average time to return top-k search results |
Technical Stack
Technical Stack
Models: OpenAI Ada-002 (embedding generation), OpenAI GPT-3.5 (rag_llm querying)
Frameworks: Pinecone (Vector Database), LangChain (RAG Orchestration), Python (NLTK, scikit-learn, gensim)
Data Sources: CMU Student Handbook (Fall 2024 Version)
Outputs: Vector store with embedded chunks, query retrievals, similarity scores, LLM responses with quality evaluations
Models: OpenAI Ada-002 (embedding generation), OpenAI GPT-3.5 (rag_llm querying)
Frameworks: Pinecone (Vector Database), LangChain (RAG Orchestration), Python (NLTK, scikit-learn, gensim)
Data Sources: CMU Student Handbook (Fall 2024 Version)
Outputs: Vector store with embedded chunks, query retrievals, similarity scores, LLM responses with quality evaluations
Technical Stack
Models: OpenAI Ada-002 (embedding generation), OpenAI GPT-3.5 (rag_llm querying)
Frameworks: Pinecone (Vector Database), LangChain (RAG Orchestration), Python (NLTK, scikit-learn, gensim)
Data Sources: CMU Student Handbook (Fall 2024 Version)
Outputs: Vector store with embedded chunks, query retrievals, similarity scores, LLM responses with quality evaluations
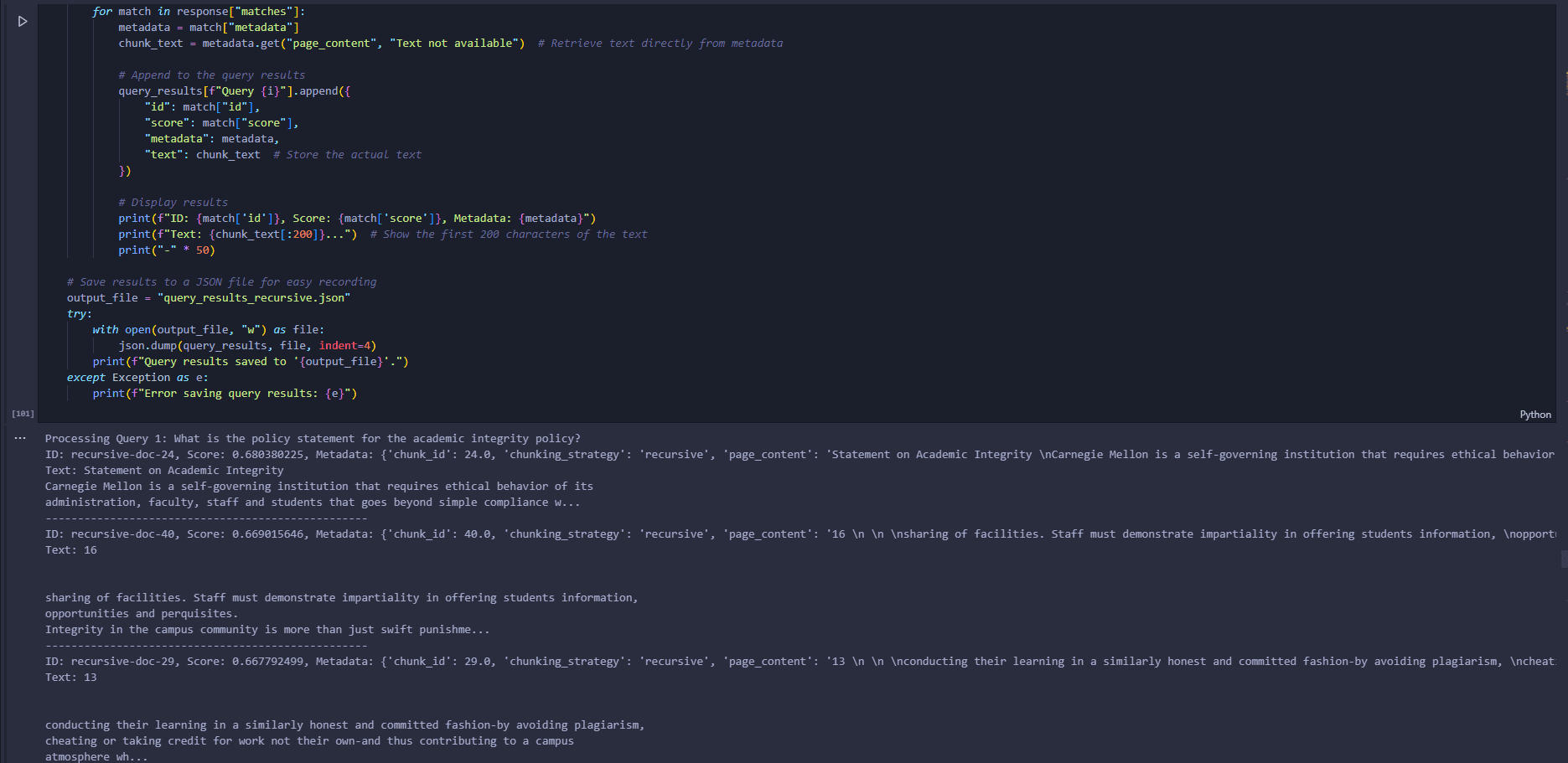
Key Results
Achieved 85–90% query-to-retrieval semantic match rate with Cosine similarity and recursive chunking
Identified k = 10 as the optimal retrieval parameter balancing relevance and noise
Demonstrated LLM response quality is highly dependent on retrieval context richness
Recommended chunk size optimizations to improve retrieval and reduce hallucinations
Constraints, Risks, and Mitigations
Constraint / Risk | Impact | Mitigation Strategy |
|---|---|---|
Chunking Granularity Impact | Loss of contextual meaning in small chunks | Adjust chunk size and overlap configurations |
Embedding Limitations | Missed nuances in dense or complex text | Test alternative embedding models if scaling |
LLM Hallucinations | Misinformation if the context is insufficient | Ensure robust retrieval and prompt engineering |
Vector Store Query Costs | API usage limits and cost management | Optimize 'k' values, batch queries where possible |
Business Impact
Demonstrates effective application of RAG techniques for real-world information retrieval use cases
Reduces manual search time and improves access to official institutional policies
Provides a replicable framework for deploying similar RAG-based document search systems across industries
Enhances user trust by increasing transparency and accuracy in information retrieval
Future Roadmap
Short-Term
Expand evaluation metrics to include BLEU and ROUGE scoring for LLM outputs
Explore hybrid retrieval methods (dense + sparse retrieval)
Mid-Term
Fine-tune embeddings with custom datasets for higher semantic precision
Deploy an interface allowing students to directly query the handbook using natural language
Long-Term
Extend the system to other campus documents (housing policies, course catalogs)
Build a feedback loop for continual vector store and model improvement based on user queries
Key Results
Achieved 85–90% query-to-retrieval semantic match rate with Cosine similarity and recursive chunking
Identified k = 10 as the optimal retrieval parameter balancing relevance and noise
Demonstrated LLM response quality is highly dependent on retrieval context richness
Recommended chunk size optimizations to improve retrieval and reduce hallucinations
Constraints, Risks, and Mitigations
Constraint / Risk | Impact | Mitigation Strategy |
|---|---|---|
Chunking Granularity Impact | Loss of contextual meaning in small chunks | Adjust chunk size and overlap configurations |
Embedding Limitations | Missed nuances in dense or complex text | Test alternative embedding models if scaling |
LLM Hallucinations | Misinformation if the context is insufficient | Ensure robust retrieval and prompt engineering |
Vector Store Query Costs | API usage limits and cost management | Optimize 'k' values, batch queries where possible |
Business Impact
Demonstrates effective application of RAG techniques for real-world information retrieval use cases
Reduces manual search time and improves access to official institutional policies
Provides a replicable framework for deploying similar RAG-based document search systems across industries
Enhances user trust by increasing transparency and accuracy in information retrieval
Future Roadmap
Short-Term
Expand evaluation metrics to include BLEU and ROUGE scoring for LLM outputs
Explore hybrid retrieval methods (dense + sparse retrieval)
Mid-Term
Fine-tune embeddings with custom datasets for higher semantic precision
Deploy an interface allowing students to directly query the handbook using natural language
Long-Term
Extend the system to other campus documents (housing policies, course catalogs)
Build a feedback loop for continual vector store and model improvement based on user queries
Key Results
Achieved 85–90% query-to-retrieval semantic match rate with Cosine similarity and recursive chunking
Identified k = 10 as the optimal retrieval parameter balancing relevance and noise
Demonstrated LLM response quality is highly dependent on retrieval context richness
Recommended chunk size optimizations to improve retrieval and reduce hallucinations
Constraints, Risks, and Mitigations
Constraint / Risk | Impact | Mitigation Strategy |
|---|---|---|
Chunking Granularity Impact | Loss of contextual meaning in small chunks | Adjust chunk size and overlap configurations |
Embedding Limitations | Missed nuances in dense or complex text | Test alternative embedding models if scaling |
LLM Hallucinations | Misinformation if the context is insufficient | Ensure robust retrieval and prompt engineering |
Vector Store Query Costs | API usage limits and cost management | Optimize 'k' values, batch queries where possible |
Business Impact
Demonstrates effective application of RAG techniques for real-world information retrieval use cases
Reduces manual search time and improves access to official institutional policies
Provides a replicable framework for deploying similar RAG-based document search systems across industries
Enhances user trust by increasing transparency and accuracy in information retrieval
Future Roadmap
Short-Term
Expand evaluation metrics to include BLEU and ROUGE scoring for LLM outputs
Explore hybrid retrieval methods (dense + sparse retrieval)
Mid-Term
Fine-tune embeddings with custom datasets for higher semantic precision
Deploy an interface allowing students to directly query the handbook using natural language
Long-Term
Extend the system to other campus documents (housing policies, course catalogs)
Build a feedback loop for continual vector store and model improvement based on user queries
More Works More Works
More Works More Works

OPEN AI - RED TEAMING
RED TEAMING + GEN AI + CHATGPT
2024
2024
OPEN AI - RED TEAMING
RED TEAMING + GEN AI + CHATGPT
2024
2024
OPEN AI - RED TEAMING
RED TEAMING + GEN AI + CHATGPT
2024
2024
OPEN AI - RED TEAMING
RED TEAMING + GEN AI + CHATGPT
2024
2024

CMU - AI FORGE
STRATEGY + GAME DEV + AI NPCS
2024
2024
CMU - AI FORGE
STRATEGY + GAME DEV + AI NPCS
2024
2024
CMU - AI FORGE
STRATEGY + GAME DEV + AI NPCS
2024
2024
CMU - AI FORGE
STRATEGY + GAME DEV + AI NPCS
2024
2024